This new post was born because of my curiosity about this tweet:
Italy 1960-2014: Big drop in annual number of births, big increase in ages of mothers. #Italy #fertility pic.twitter.com/QGT0AnA3IU
— Carl Schmertmann (@CSchmert) 7 de febrero de 2018
Sometimes you just feel the urge to recreate some data analysis that you find interesting. Im my case I used data from Spain that I found in INE (National Institute of Statistics), with a little effort I found out the ftp where the data are hidden.
And here you have some code to play with this beautiful data set. It’s a little tricky because its codification has changed several times in the last years.
#nacimientos
suppressPackageStartupMessages(library(dplyr))
suppressPackageStartupMessages(library(ggplot2))
suppressPackageStartupMessages(library(readr))
DescargaNacimientos <- function(year){
if (year %in% 2007:2010){
url <- sprintf("ftp://www.ine.es/temas/mnp_nacim/datos%%20nacimientos%s.zip",substr(year,3,4))
}
if (year %in% 2011:2015){
url <- sprintf("ftp://www.ine.es/temas/mnp_nacim/datos_nacimientos%s.zip",substr(year,3,4))
}
if (year %in% 1996:2006){
url <- sprintf("ftp://www.ine.es/temas/mnp_nacim/datos%%20nacimientos%%20%s.zip",substr(year,3,4))
}
if (year %in% 1980:1995){
url <- sprintf("ftp://www.ine.es/temas/mnp_nacim/datos%%20nacimientos%%20%s.zip",substr(year,3,4))
}
if (year %in% 1975:1979){
url <- sprintf("ftp://www.ine.es/temas/mnp_nacim/datos%%20nacimientos%%20%s.zip",substr(year,3,4))
}
download.file(url = url,destfile = "nacimientos.zip",quiet = TRUE)
filename <- unzip(zipfile = "nacimientos.zip",list = TRUE)$Name
unzip("nacimientos.zip")
unlink("nacimientos.zip")
nacimientos <- TraduceNacimientos(filename,year)
unlink(filename)
return(nacimientos)
}
TraduceNacimientos <- function(file,year){
if (year %in% 1975:1979){
columnas.name <- c("MUNRC","PROVRC","MESNA","AÑONA","SEXO","LEGI","LUGAR","PS","MULTI","NATURI","NOD","MESNM","AÑONM","PROFM","N1","MESMM","AÑOMM","NUMHIJOS","MESNACUH","AÑONACUH","MUNIRES","PROVRES","MESNP","AÑONP","PROFP","ANCUM","ANCUP","INTERG")
columnas.ancho <- c(3,2,2,2,1,1,1,1,1,1,1,2,2,2,1,2,2,2,2,2,3,2,2,2,2,2,2,2)
}
if (year %in% 1980:1995){
columnas.name <- c("MUNRC","PROVRC","LUGAR","ASANIT","SEMGEST","MESPA","AÑOPA","MULTI","NATURI","NORMAL","MESNM","AÑONM","PROFM","MUNIRES","PROVRES","NUMHIV","MESPANT","AÑOPANT","CASADA","CASAPV","MESMAC","AÑOMAC","MESNP","AÑONP","PROFP")
columnas.ancho <- c(3,2,1,1,2,2,2,1,1,1,2,2,2,3,2,2,2,2,1,1,2,2,2,2,2)
}
if (year %in% 1996:2006){
columnas.name <- c("CMUNI","CPROI","MESPAR","ANOPAR","SEMGES","LUGNAC","PARASIS","MULTI","NATURI","NORMAL","MESNM","AÑONM","PROFM","MUNM","PROVM","NUMHV","MESHAN","AÑOHAN","CAS","CASP","MESMAT","AÑOMAT","MESNP","AÑONP","PROFP","TMUNIN","TMUNR","EDADM","EDADMM","ANOCA","ININHA","EDADP","SEXO","NACV","V24HN","PESON","CODCAUN","CODCAU4N","NACMAD","NACPAD")
columnas.ancho <- c(3,2,2,4,2,1,1,1,1,1,2,4,2,3,2,2,2,4,1,1,2,4,2,4,2,1,1,2,2,2,3,2,1,1,1,4,3,1,3,3)
}
if (year %in% 2007:2015){
columnas.name <- c("PROI","MUNI","MESPAR","ANOPAR","PROPAR","MUNPAR","LUGARPA","ASISTIDO","MULTIPLI","NORMA","CESAREA","INTERSEM","SEMANAS","MESNACM","AÑONACM","NACIOEM","NACIOXM","PAISNACM","CUANNACM","PROMA","MUNMA","PAISNXM","PROREM","MUNREM","PAISRXM","ESTUDIOM","CAUTOM","ECIVM","CASPNM","MESMAT","AÑOMAT","PHECHO","ESTABLE1","MESEST1","AÑOEST1","NUMH","NUMHV","MESHAN","AÑOHAN","PROHANTE","MUNHANTE","PAISHANTX","NACIOEHA","NACIOXHA","PAISNAHA","MESNACP","AÑONACP","NACIOEP","NACIOXP","PAISNACP","CUANNACP","PROPA","MUNPA","PAISNXP","DONDEP","PROREP","MUNREP","PAISRXP","ESTUDIOP","CAUTOP","TMUNIN","TMUNNM","TMUNNP","TMUNNHA","TMUNRM","TMUNRP","TPAISNACIMIENTOMADRE","TPAISNACIMIENTOPADRE","TPAISNACIMIENTOHIJOANTE","TPAISRMADRE","TPAISRPADRE","TPAISNACIONALIDADMADRE","TPAISNACIONALIDADPADRE","TPAISNACIONALIDADHIJOANT","TPAISNACIONALIDADNACIDO","EDADM","EDADMM","EDADMREL","ANOCA","ANOREL","INIHA","BLANCOS1","EDADP","NACIOEN","NACIOXN","PAISNACN","SEXO","PESON","V24HN","NACVN","AUTOPSN","MUERN","CODCA1N","CODCA2N","CODCA4N","CLASIF","SORDENV","NUMHVT","TMUNPAR","BLANCOS2")
columnas.ancho <- c(2,3,2,4,2,3,1,1,1,1,1,1,2,2,4,1,1,3,1,2,3,3,2,3,3,2,2,1,1,2,4,1,1,2,4,2,2,2,4,2,3,3,1,1,3,2,4,1,1,3,1,2,3,3,1,2,3,3,2,2,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,2,2,2,2,2,3,3,2,1,1,3,1,4,1,1,1,1,1,2,1,1,2,2,1,17)
}
nacimientos <- suppressMessages(read_fwf(file = file,col_positions = fwf_widths(columnas.ancho,columnas.name),progress = TRUE))
return(nacimientos)
}Edad de los padres y peso del nacido entre 1996 y 2015
years <- 1996:2015
nacimientos <- vector("list",length(years))
n <- 1
for (y in years){
nacimientos[[n]] <- suppressMessages(DescargaNacimientos(year = y))
nacimientos[[n]] <- nacimientos[[n]] %>% select(ANOPAR,EDADM,EDADP,PESON)
nacimientos[[n]] <- as.data.frame(sapply( nacimientos[[n]], as.numeric ))
n <- n+1
}
nacimientos <- bind_rows(nacimientos)suppressPackageStartupMessages(library(dplyr))
suppressPackageStartupMessages(library(ggplot2))
suppressPackageStartupMessages(library(readr))
g1 <- ggplot(data = nacimientos,aes(x=as.factor(ANOPAR),y=EDADM)) + geom_boxplot(outlier.alpha = 0.1) + labs(title="Edad media de las madres",subtitle="Nacimientos 1996-2015",caption="Fuente: INE") + xlab("Año")
plot(g1)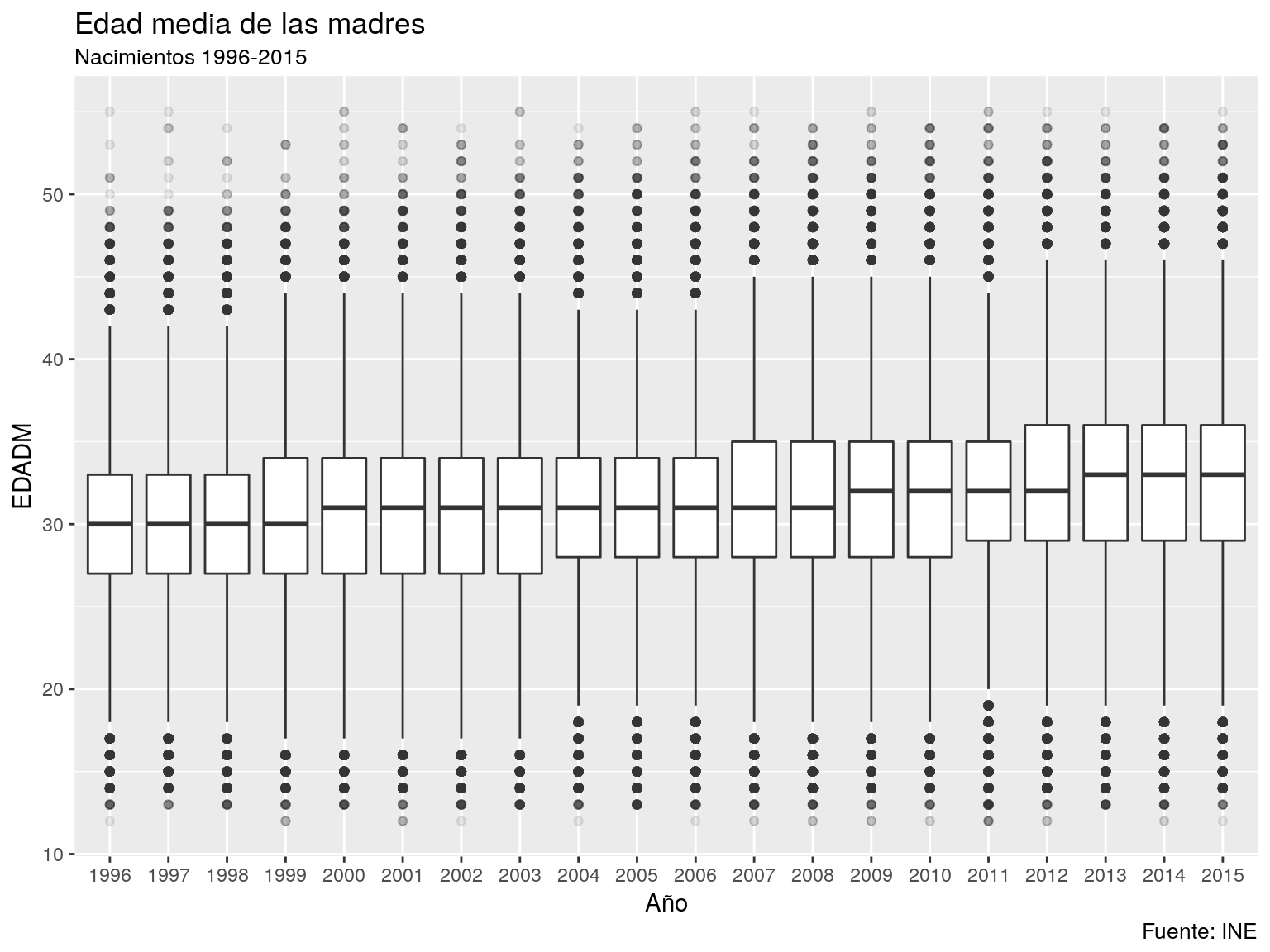
g2 <- ggplot(data = nacimientos,aes(x=as.factor(ANOPAR),y=EDADP)) + geom_boxplot(outlier.alpha = 0.1) + labs(title="Edad media de los padres",subtitle="Nacimientos 1996-2015",caption="Fuente: INE") + xlab("Año")
plot(g2)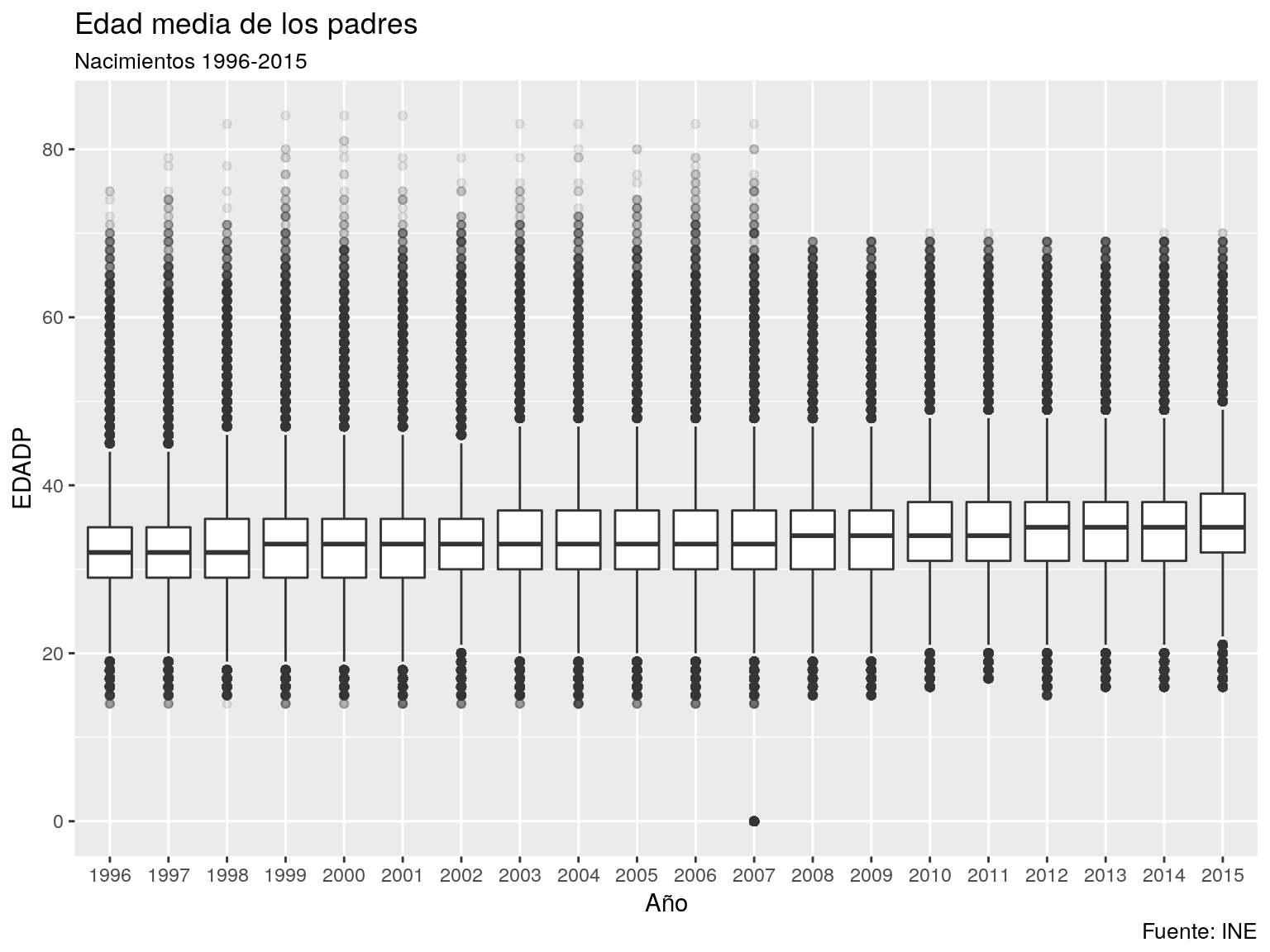
g4 <- ggplot(data=nacimientos,aes(x=as.factor(EDADM),y=PESON)) + geom_boxplot(outlier.alpha = 0.1) + labs(title="Peso medio de los nacidos según edad de la madre",subtitle="Nacimientos 1996-2015",caption="Fuente: INE") + xlab("Edad")
plot(g4)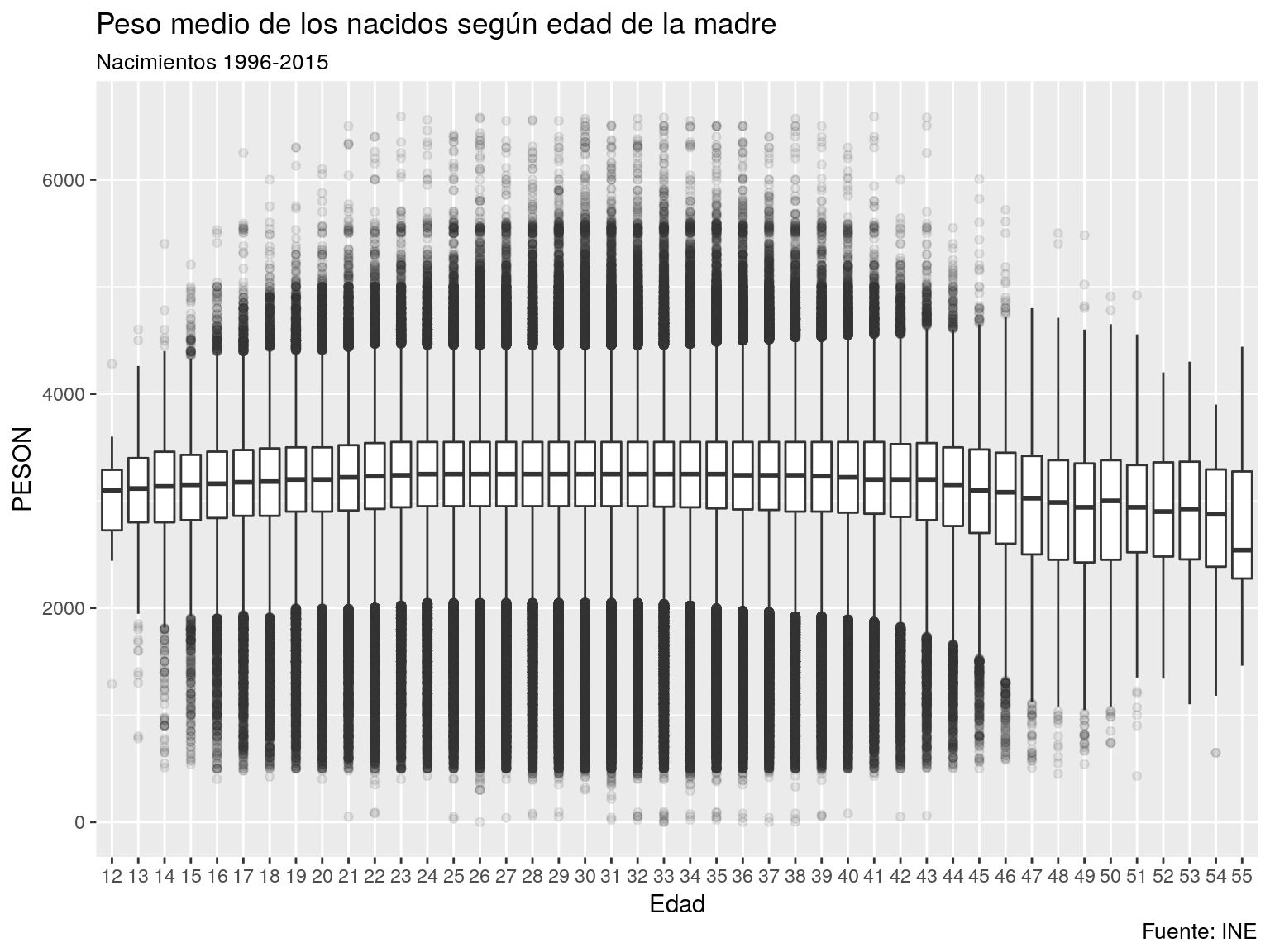
years <- 1975:2015
nacimientosP <- vector("list",length(years))
n <- 1
for (y in years){
nacimientosP[[n]] <- DescargaNacimientos(year = y)
if (y %in% 1975:1979){
fechana <- ISOdate(year = 1900+nacimientosP[[n]]$AÑONA,month = nacimientosP[[n]]$MESNA,day = 1)
fechama <- ISOdate(year = 1900+nacimientosP[[n]]$AÑONM,month = nacimientosP[[n]]$MESNM,day = 1)
nacimientosP[[n]]$EDADM <- round(difftime(fechana,fechama,units = "days")/365)
nacimientosP[[n]]$NUMHV <- nacimientosP[[n]]$NUMHIJOS
nacimientosP[[n]]$ANOPAR <- 1900 + nacimientosP[[n]]$AÑONA
}
if (y %in% 1980:1995){
fechana <- ISOdate(year = 1900+nacimientosP[[n]]$AÑOPA,month = nacimientosP[[n]]$MESPA,day = 1)
fechama <- ISOdate(year = 1900+nacimientosP[[n]]$AÑONM,month = nacimientosP[[n]]$MESNM,day = 1)
nacimientosP[[n]]$EDADM <- round(difftime(fechana,fechama,units = "days")/365)
nacimientosP[[n]]$NUMHV <- nacimientosP[[n]]$NUMHIV
nacimientosP[[n]]$ANOPAR <- 1900 + nacimientosP[[n]]$AÑOPA
}
nacimientosP[[n]] <- nacimientosP[[n]] %>% dplyr::filter(NUMHV=="01") %>% select(ANOPAR,EDADM)
nacimientosP[[n]] <- as.data.frame(sapply( nacimientosP[[n]], as.numeric ))
n <- n+1
}
nacimientos <- bind_rows(nacimientosP)suppressPackageStartupMessages(library(dplyr))
suppressPackageStartupMessages(library(ggplot2))
suppressPackageStartupMessages(library(readr))
g1 <- ggplot(data = nacimientos,aes(x=as.factor(ANOPAR),y=EDADM)) + geom_boxplot(outlier.alpha = 0.1) + labs(title="Edad media de las madres primerizas",subtitle="Nacimientos 1975-2015",caption="Fuente: INE") + xlab("Año")
plot(g1)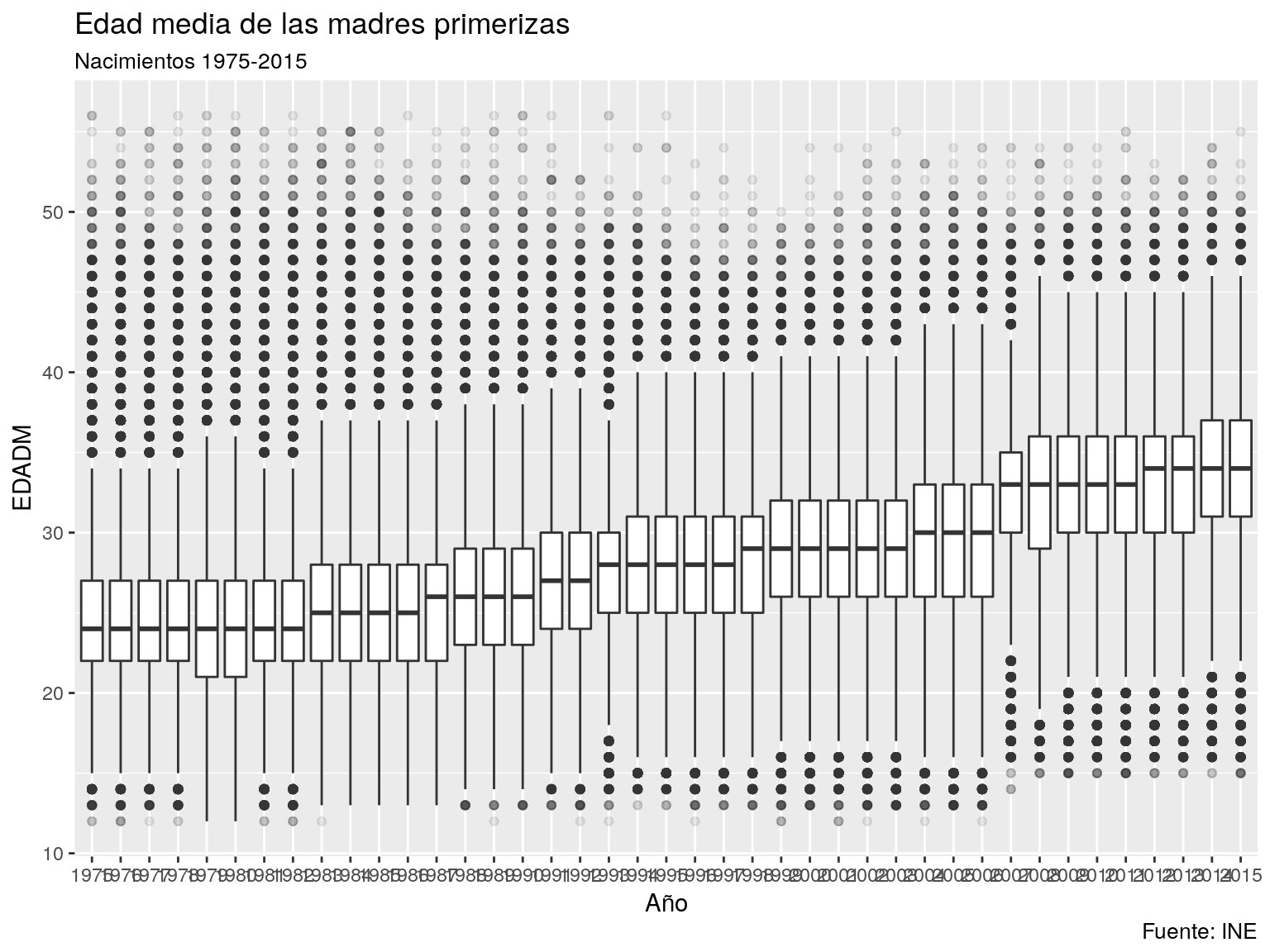
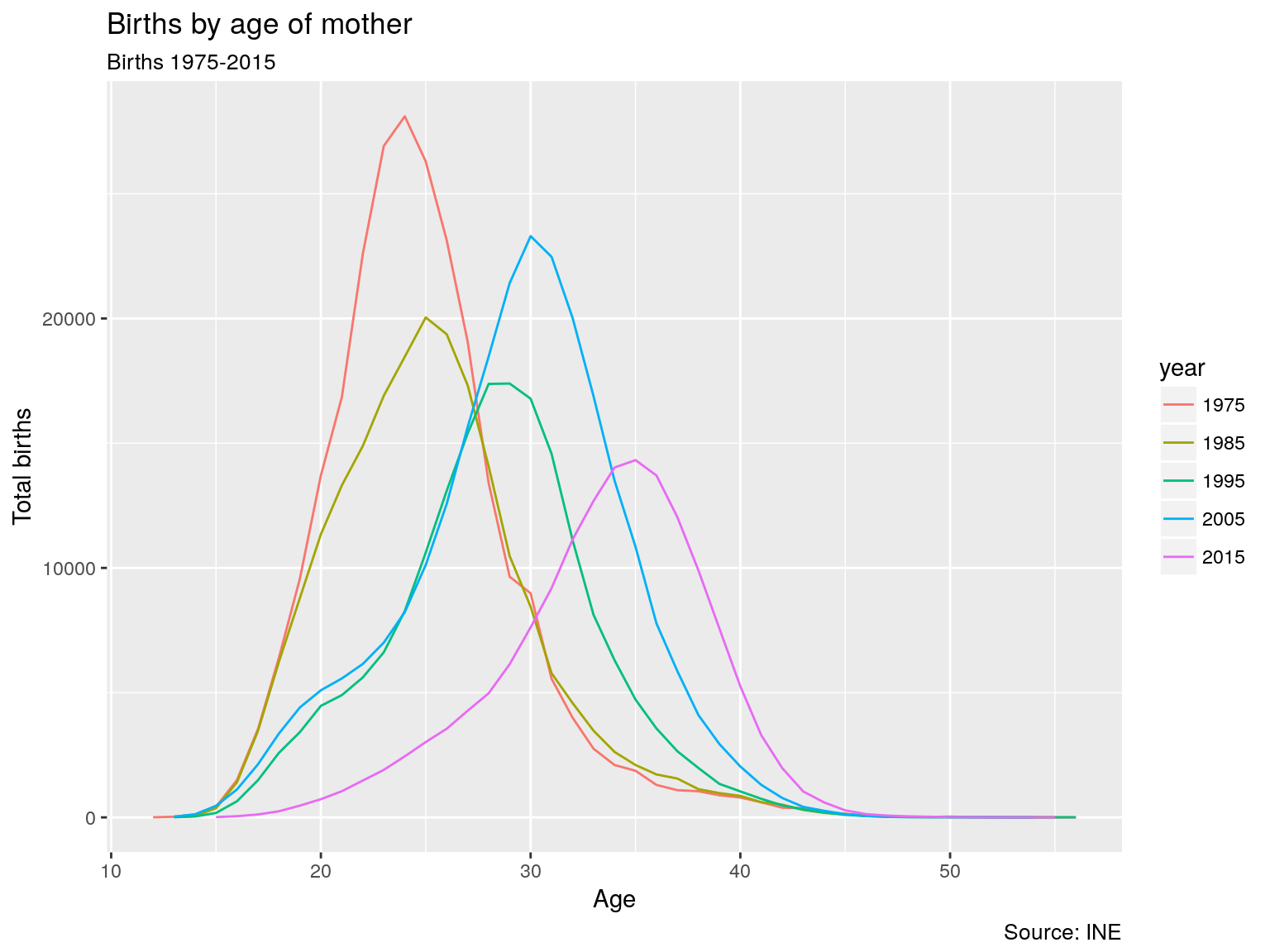
nacimientos10 <- nacimientos %>% dplyr::filter(ANOPAR %in% seq(1975,2015,10))
nacimientos10$year <- as.factor(nacimientos10$ANOPAR)
nacimientos10.age <- nacimientos10 %>% dplyr::group_by(year,EDADM) %>% dplyr::summarise(total=n())
g3 <- ggplot(nacimientos10.age) + geom_line(aes(x=EDADM,y=total,color=year))+ labs(title="Births by age of mother",subtitle="Births 1975-2015",caption="Source: INE") + xlab("Age") + ylab("Total births")
plot(g3)