Introduction
Maybe some of you (in my huge audience) have the bad luck of being allergic to pollen like myself. Since mid-January to the end of June I have to live very close to my antihistamines. Here in Madrid where I live health authorities issue newsletters (by email) with observations and forecast.
Although the service has some deficiencies (like not being available in weekends and fairy days) I found it useful, but how good are the forecasts provided? Let’s take a look.
The data
Some years ago I made a request for the historical data of pollen observations from Comunidad de Madrid. I never got an answer so I decided to scrap he data from the pdf in the emails. Quite hard.
Here you have some code to download the attachments from the email sent by sanidadambiental.polen@salud.madrid.org
library(httr)
library(gmailr)
saveAttachaments = function(id,folder)
{
save_attachments(message(id),path=folder)
}
gmail_auth(secret = "SECRET",scope = "read_only",id = "ID")
mensajes <- messages("from:sanidadambiental.polen@salud.madrid.org",700)
id.mensajes <- id(mensajes)
for (i in 1:length(id.mensajes)){
date <- as.POSIXct(as.numeric(message(id(mensajes)[i])$internalDate)/1000,origin="1970-01-01")
date <- as.character(date,format="%Y%m%d")
print(date)
folder <- sprintf("attach/%s",date)
dir.create(folder,showWarnings = FALSE)
saveAttachaments(id.mensajes[i],folder)
}With a little patience you get a folder for every email with de pdf files attached inside.
The data
You all know pdf files are not good to data transfer but this is what I have, so I have to work with it. Now I show an example of pdf file with the observations:
Pdf file with observations
To scrap the observations data from these pdf files I use this code with the tabulizer package (Disclaimer: this code is quite old, and old code can be embarrasing)
readPDFobservaciones_tabulizer <- function(tipo="CUPR",fecha){
if(file.exists(sprintf("attach/%s/%s.pdf",fecha,tipo))){
pdffile <- sprintf("attach/%s/%s.pdf",fecha,tipo)
table <- extract_tables(file = pdffile)[[1]]
coltables <- table[1,]
#si hay columna media la quito porque da problemas y la puedo calcular a posterior
if ("media" %in% tolower(coltables)){
table <- table[,-which(tolower(coltables)=="media")]
} else {
#si no hay es la ultima columna
table <- table[,-ncol(table)]
}
coltables <- c("fechas",table[1,])
#si hay alguna columna con todo vacio la quitamos
columnas <- which(apply(table,2,FUN=function(x) sum(x!=""))==0)
if (length(columnas)!=0){
table <- table[,-columnas]
}
filas <- which(apply(table,1,FUN=function(x) sum(x!=""))==0)
if (length(filas)!=0){
table <- table[-filas,]
}
coltables <- coltables[coltables!=""]
table <- as.data.frame(table[-1,])
colnames(table) <- coltables
#un poco de tuneo de los nombre de las columnas
cols <- colnames(table)
cols <- gsub(pattern = "Media",replacement = "",cols)
cols <- gsub(pattern = 'Madrid-.* ',"",cols)
cols[cols=="Madrid-Arganzuela"] <- "Arganzuela"
cols[cols=="Barrio"] <- "Salamanca"
cols[cols=="Ciudad"] <- "Universitaria"
colnames(table) <- cols
return(table)
} else {
print("Ese archivo no existe")
}
}
SerieObservaciones <- function(tipo="CUPR"){
lf <- list.dirs("attach/",full.names = FALSE)
obs <- list()
n <- 1
for (l in lf){
print(l)
#o <- readPDFobservaciones(fecha=l)
o <- readPDFobservaciones_tabulizer(fecha=l)
if (is.data.frame(o)){
obs[[n]] <- o
n <- n+1
}
}
fechas <- unique(bind_rows(obs)$fechas)
fechas <- fechas[!is.na(fechas)]
cols <- colnames(obs[[which(sapply(obs, ncol)==max(sapply(obs, ncol)))[1]]])
obs.def <- as.data.frame(matrix(NA,nrow=length(fechas),ncol=length(cols)))
colnames(obs.def) <- cols
obs.def$fechas <- fechas
#relleno el pavo
for (i in 1:length(obs)){
print(i)
for (r in 1:nrow(obs[[i]])){
o <- obs[[i]][r,]
if(!is.na(o$fecha)){
#print(o$fecha)
columnas.quetengo <- colnames(o)[colnames(o) %in% cols]
columnas.quetengo <- columnas.quetengo[columnas.quetengo!="fechas"]
obs.def[obs.def$fechas==o$fecha,columnas.quetengo] <- as.integer(o[,columnas.quetengo])
}
}
}
obs.def$media <- rowMeans(obs.def[,-1],na.rm = TRUE)
return(obs.def)
}Forecast appears as an image in the body of the email and here you have the code to read it based in the color of the image
readPrediccionesPDF <- function(tipo="CUPR",fecha){
if (tipo=="CUPR") {
texto <- "Cupre"
texto2 <- "cup"
}
lf <- list.files(path=sprintf("attach/%s",fecha))
file <- lf[grep(texto,lf)]
file <- c(file,lf[grep(tipo,lf)])
file <- c(file,lf[grep(texto2,lf)])
file <- file[file!="CUPR.pdf"]
if (length(file)>0){
file <- file[which(nchar(file)==max(nchar(file)))]
command <- sprintf('pdfimages -j attach//%s//"%s" image',fecha,file)
system(command)
colores <- list()
valores <- character()
lf.jpg <- list.files(path=".",pattern = ".jpg")
lf.jpg <- lf.jpg[!grepl("0000.jpg",lf.jpg)]
lf.jpg <- lf.jpg[!grepl("000.jpg",lf.jpg)]
for (n in 1:4){
colores[[n]] <- raster::extract(stack(lf.jpg[n]),cbind(0,0))
if (sum(colores[[n]]==c(153,1,52))==3) {valores[n] <- "MA"}
if (sum(colores[[n]]==c(254,153,0))==3) {valores[n] <- "A"}
if (sum(colores[[n]]==c(0,129,2))==3) {valores[n] <- "M"}
if (sum(colores[[n]]==c(0,128,1))==3) {valores[n] <- "M"}
if (sum(colores[[n]]==c(48,0,100))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(255,193,214))==3) {valores[n] <- "MA"}
if (sum(colores[[n]]==c(255,197,11))==3) {valores[n] <- "A"}
if (sum(colores[[n]]==c(178,215,110))==3) {valores[n] <- "M"}
if (sum(colores[[n]]==c(50,2,102))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(51,0,101))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(236,217,245))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(237,217,245))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(62,79,105))==3) {valores[n] <- "B"}
if (sum(colores[[n]]==c(61,164,75))==3) {valores[n] <- "M"}
}
unlink(lf.jpg)
return(valores)
} else {
return(NA)
}
}
SeriePredicciones <- function(tipo="CUPR"){
lf <- list.dirs("attach/",full.names = FALSE)[-1]
preds <- list()
n <- 1
for (l in lf){
print(l)
o <- readPrediccionesPDF(fecha=l)
print(o)
if (is.character(o)){
preds[[n]] <- as.data.frame(t(c(l,o)))
n <- n+1
}
}
preds <- bind_rows(preds)
colnames(preds) <- c("fecha","D-1","D0","D1","D2")
preds$fecha <- as.Date(preds$fecha,format="%Y%m%d")
return(preds)
}In this graph you can see the complete historical series of Cupressaceae/Taxacea (my worst enemy) from 2014 to present day. Please notice the huge peak in February 2019, those were rough days.
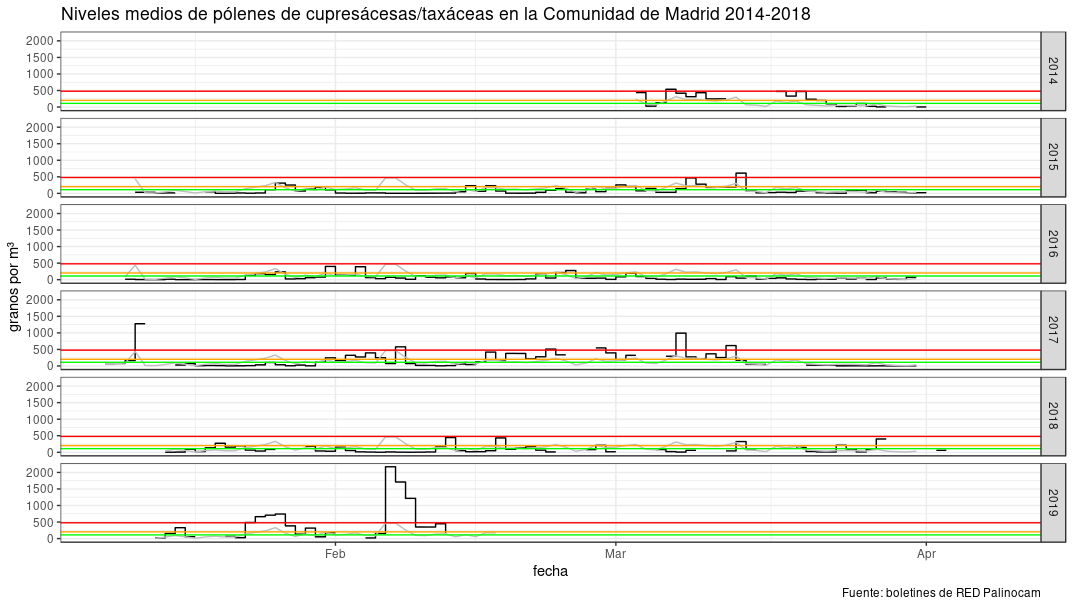
Cupressaceae-Taxaceae pollen
Finally I checked forecast quality using Gerrity Score because “GS does not reward conservative forecasting like HSS and HK, but rather rewards forecasts for correctly predicting the less likely categories”.
Gerrity Score for persistence (using yesterday observation as today forecast): 0.366
Gerrity Socre for climatology (using average value for this day as today forecast): 0.215
Gerrity Score for forecast: 0.32
So, forecast seems to be not very useful compared with persistence.